Overview
We make data unlearnable by directly maximizing Bayes error under imperceptible perturbation constraints.
Rather than relying on fragile training shortcuts, our method increases the intrinsic difficulty of classification. As a result, the protected samples remain harmful even when mixed with clean data — the realistic setting for data protection.
Motivation: Existing Protection Collapses in Mixed Data
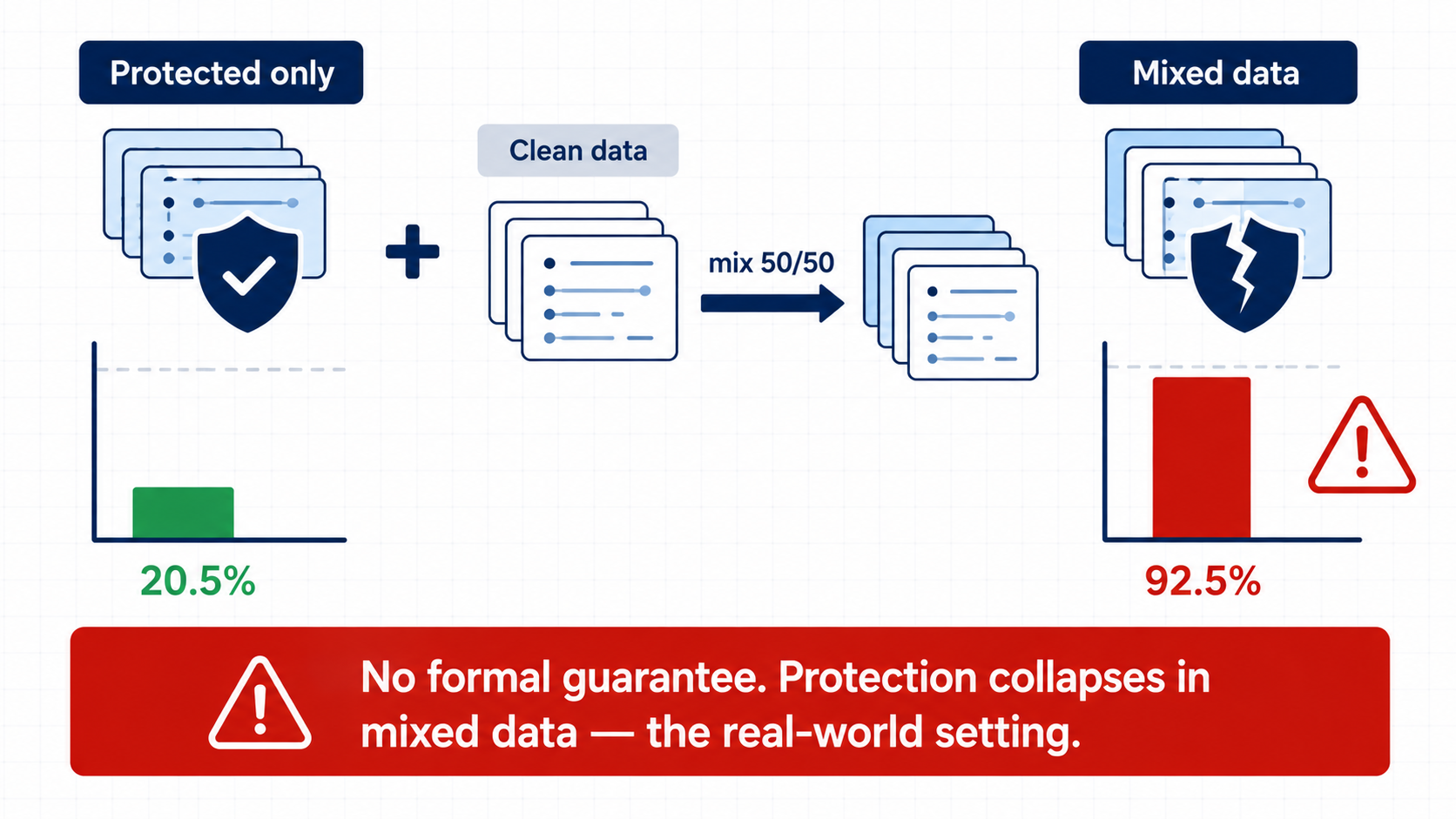
Existing unlearnable-example methods can work when all training data is protected. However, this setting is unrealistic: in practice, protected samples are usually mixed with clean data from other sources.
In the mixed-data setting, prior methods can fail badly. This motivates a different goal: instead of only perturbing the input surface, we should directly reduce the data’s intrinsic learnability.
Key Idea: Optimize Bayes Error Directly
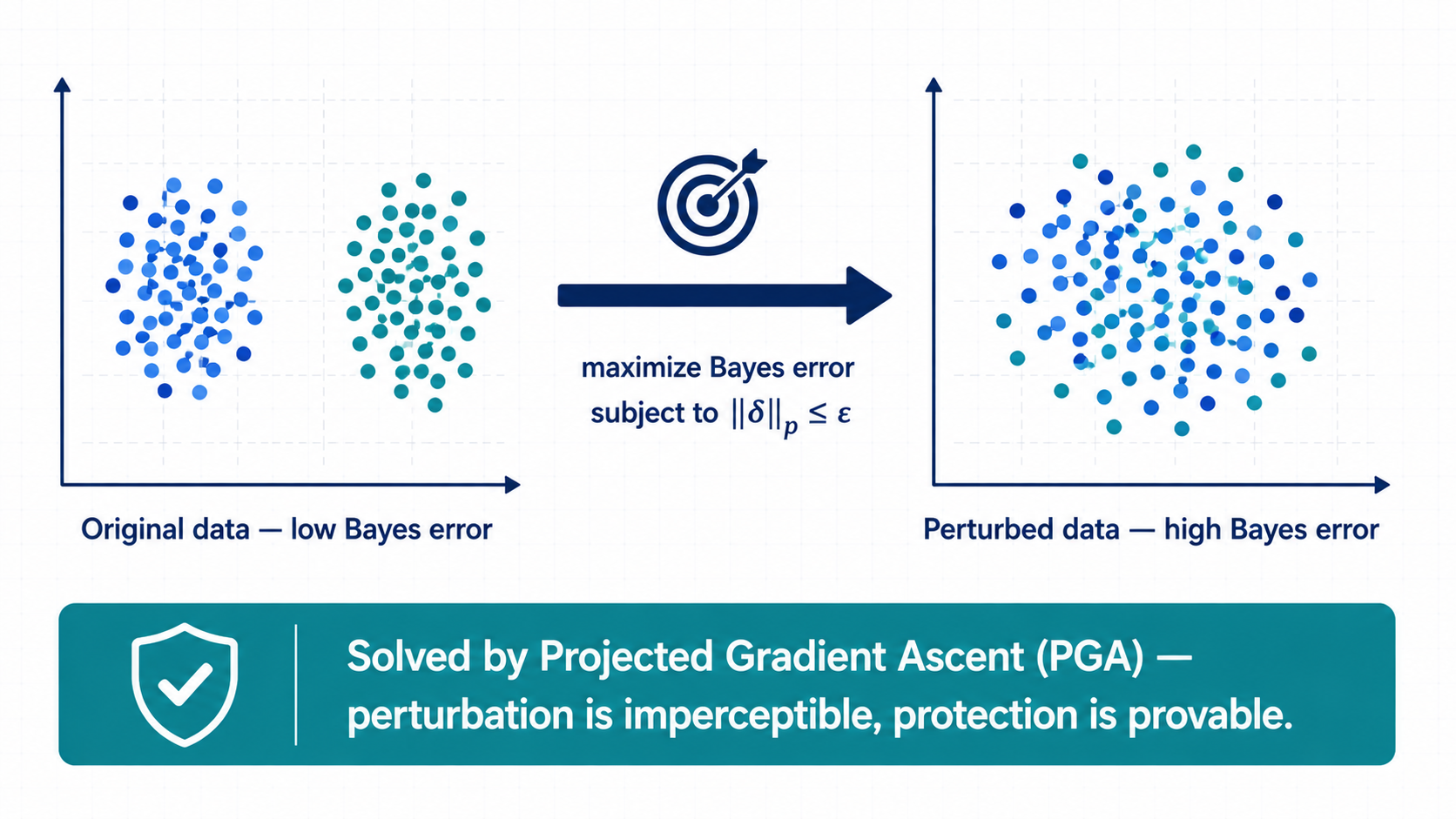
Our key idea is to treat Bayes error as the optimization target.
Bayes error measures the irreducible classification difficulty of a data distribution. If Bayes error increases, then the best possible classifier also becomes less effective.
We therefore construct unlearnable examples by solving a constrained optimization problem: maximize estimated Bayes error subject to an (L_p) perturbation budget. The optimization is solved by projected gradient ascent (PGA), so the perturbations remain imperceptible while the resulting protection is theoretically grounded.
Evaluation: Protection Holds in Mixed Data
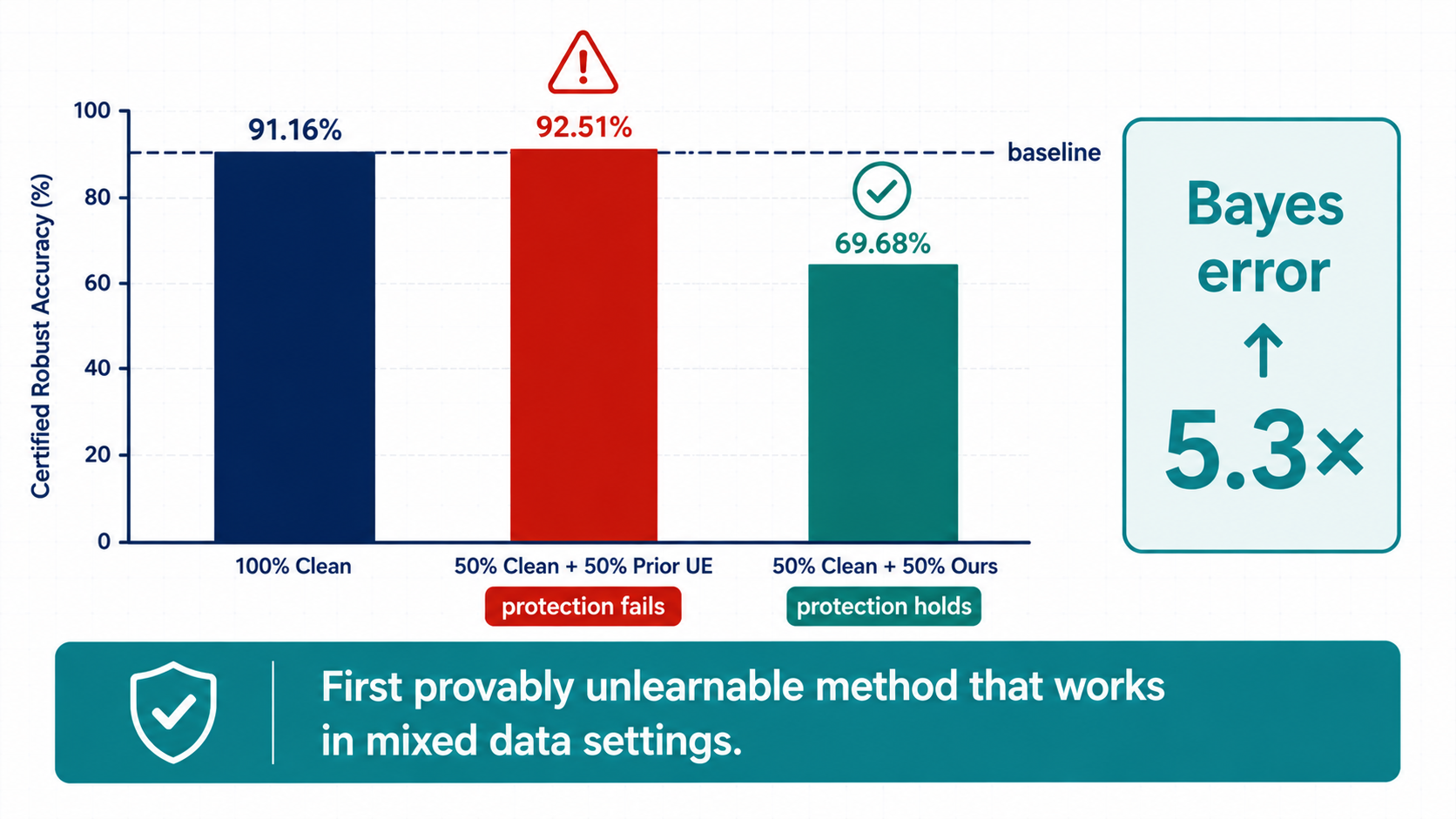
We evaluate the method in the realistic mixed-data setting.
On CIFAR-10 with a 50/50 mixture of clean and protected samples, prior methods recover to about 92.51% test accuracy, which means the protection effectively collapses. In contrast, our Bayes-error-based method reduces accuracy to 69.68%, showing that the protected samples remain meaningfully unlearnable even when mixed with clean data.
This is also accompanied by a substantial increase in Bayes error, highlighting that the method works by changing intrinsic learnability rather than exploiting a fragile training artifact.
Takeaway
Instead of relying on heuristic perturbations, we construct unlearnable examples by directly increasing Bayes error, making the data harder to learn even when mixed with clean samples.
Citation
@misc{zhang2025provablyunlearnableexamplesbayes,
title={Towards Provably Unlearnable Examples via Bayes Error Optimisation},
author={Ruihan Zhang and Jun Sun and Ee-Peng Lim and Peixin Zhang},
year={2025},
eprint={2511.08191},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2511.08191},
}