Correct-By-Construction: Certified Individual Fairness through Neural Network Training
Overview
This work addresses a fundamental challenge in trustworthy AI: how to guarantee that a neural network treats similar individuals fairly, regardless of their sensitive attributes.
Existing approaches either verify fairness after training — which is expensive and does not scale — or apply post-hoc corrections that offer no formal guarantee. We ask a different question:
Can we train a neural network such that individual fairness is guaranteed by construction, throughout the entire training process?
Motivation
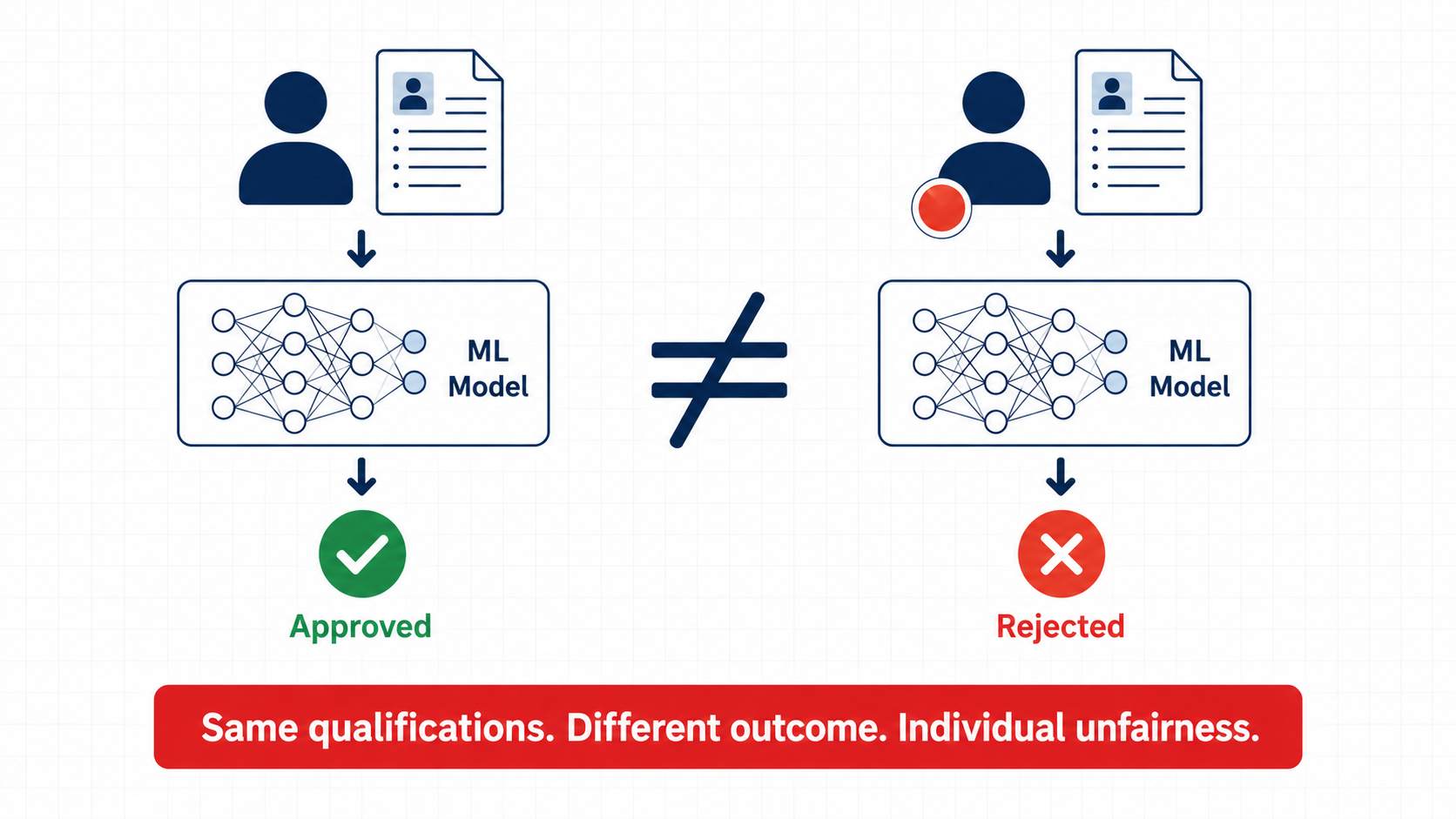
Machine learning models increasingly drive high-stakes decisions in hiring, lending, healthcare, and law. When these models encode biases against sensitive attributes — such as race or gender — the consequences are severe and often invisible to those affected.
Individual fairness requires that similar individuals receive similar outcomes, regardless of their sensitive features. This is a stronger and more precise guarantee than group fairness, but it is also much harder to certify.
The standard approach is to train a model first and verify fairness afterwards. But verification requires exploring a large or infinite input space, and it provides no guarantee that the model will remain fair under further updates. As Dijkstra noted:
Program testing can be used to show the presence of bugs, but never to show their absence.
The same applies to fairness: testing can reveal unfairness, but it cannot certify its absence.
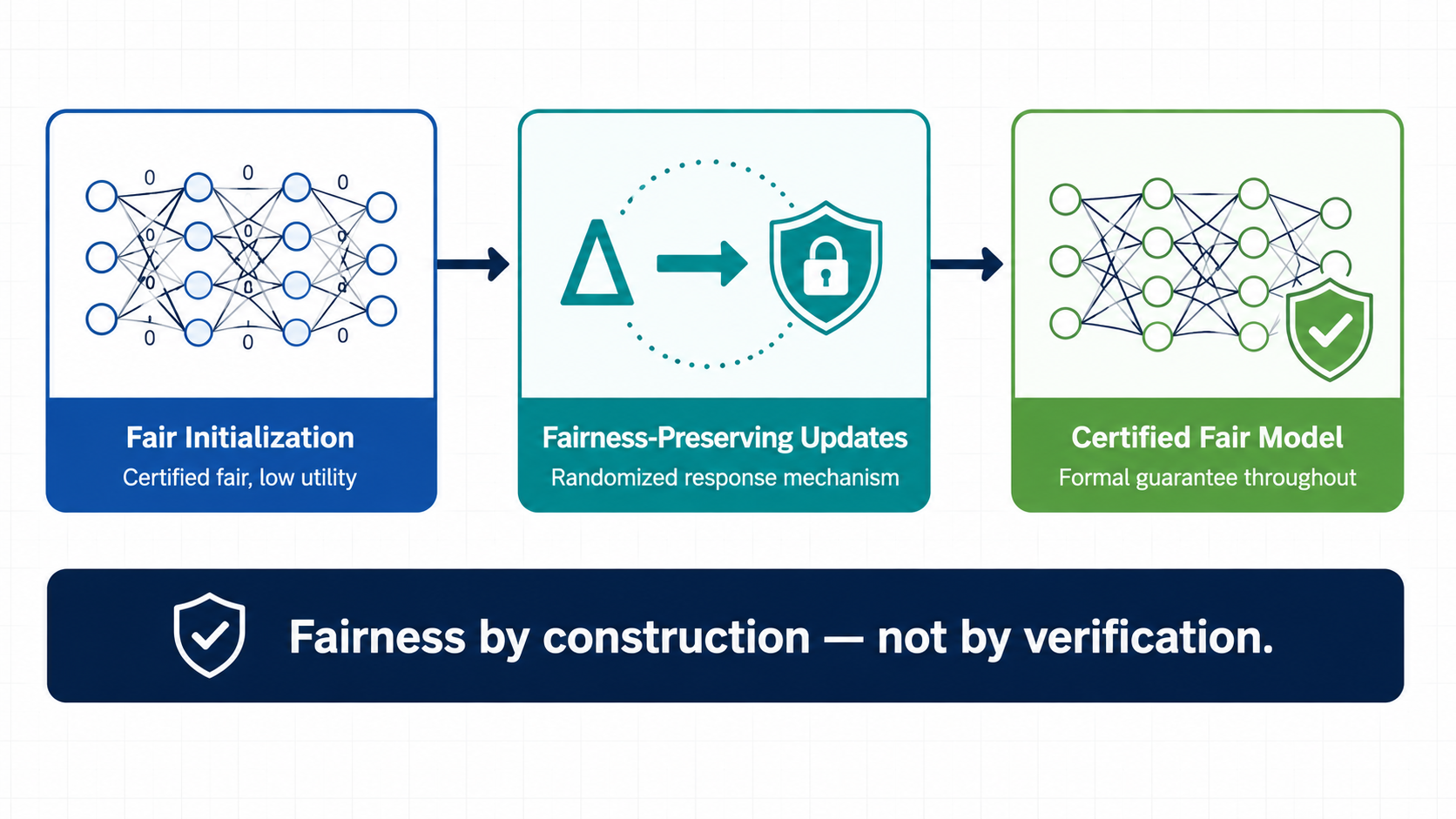
Key Idea: Correct-By-Construction
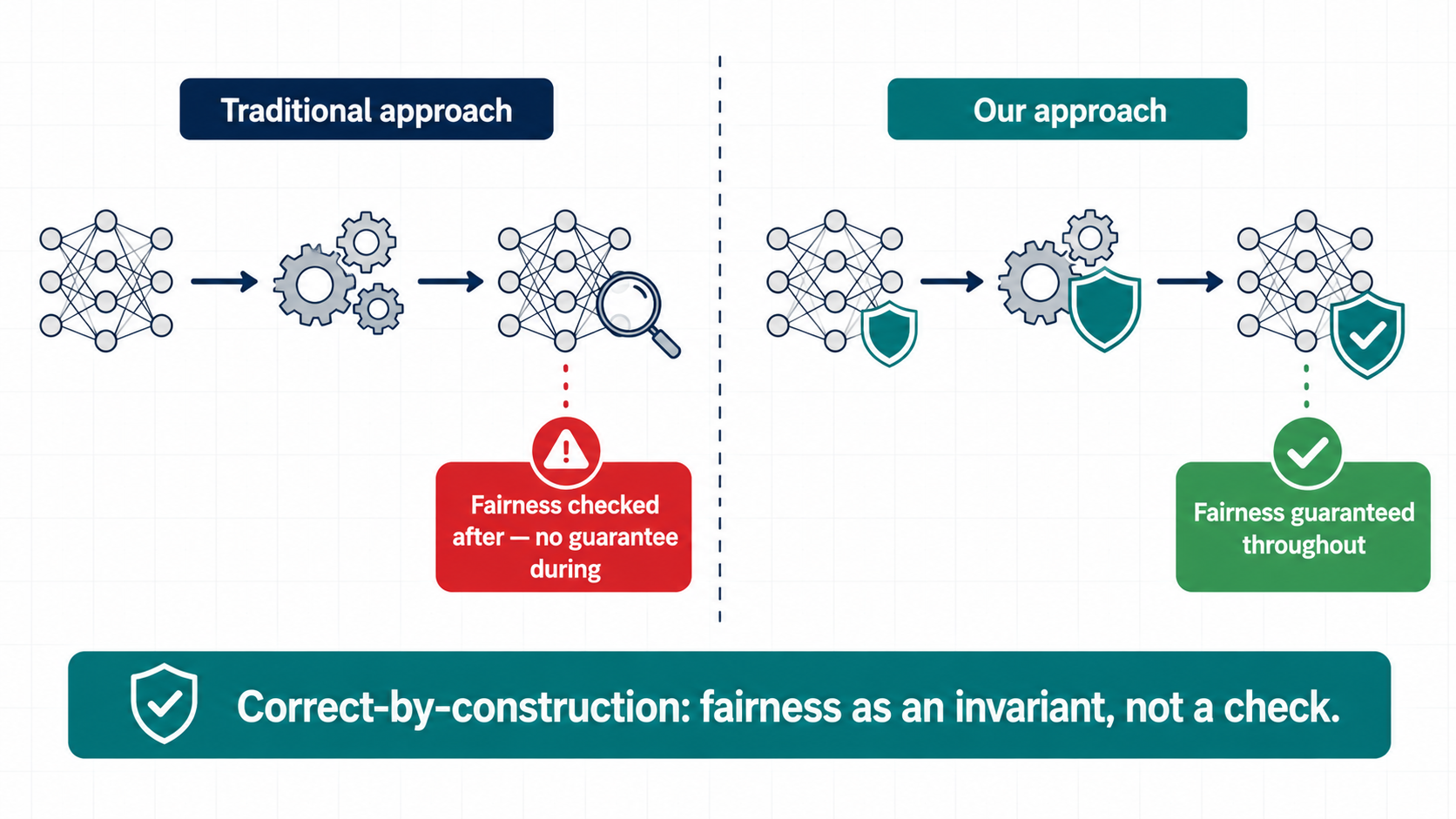
Instead of verifying fairness after training, we embed it as an invariant throughout training.
The correct-by-construction principle has two components:
- Fair initialization: start with a model that is provably fair, even if it has low utility.
- Fairness-preserving updates: train using a procedure that guarantees fairness is maintained at every step.
If both conditions hold, the final model is certified fair — not because we checked it afterwards, but because it was never allowed to become unfair.
Approach

Our approach rests on three lemmas.
Lemma 1 — Fair initialization exists. There always exist parameter settings under which a neural network produces identical outputs for all sensitive attribute values. A simple strategy is near-zero random initialization, which satisfies this condition while remaining trainable.
Lemma 2 — Composition property. If every neuron feeding into the output is individually fair, then the entire network is fair. Individual fairness cascades through the architecture.
Lemma 3 — Update property. A fair network remains fair if parameter updates satisfy one of two conditions: either the gradients summed over all sensitive attribute values cancel out, or the gradients are identical across sensitive values.
Together, these lemmas give us a training procedure that is almost identical to standard training in cost, but carries a formal fairness guarantee throughout.
Mechanism: Fairness Propagation
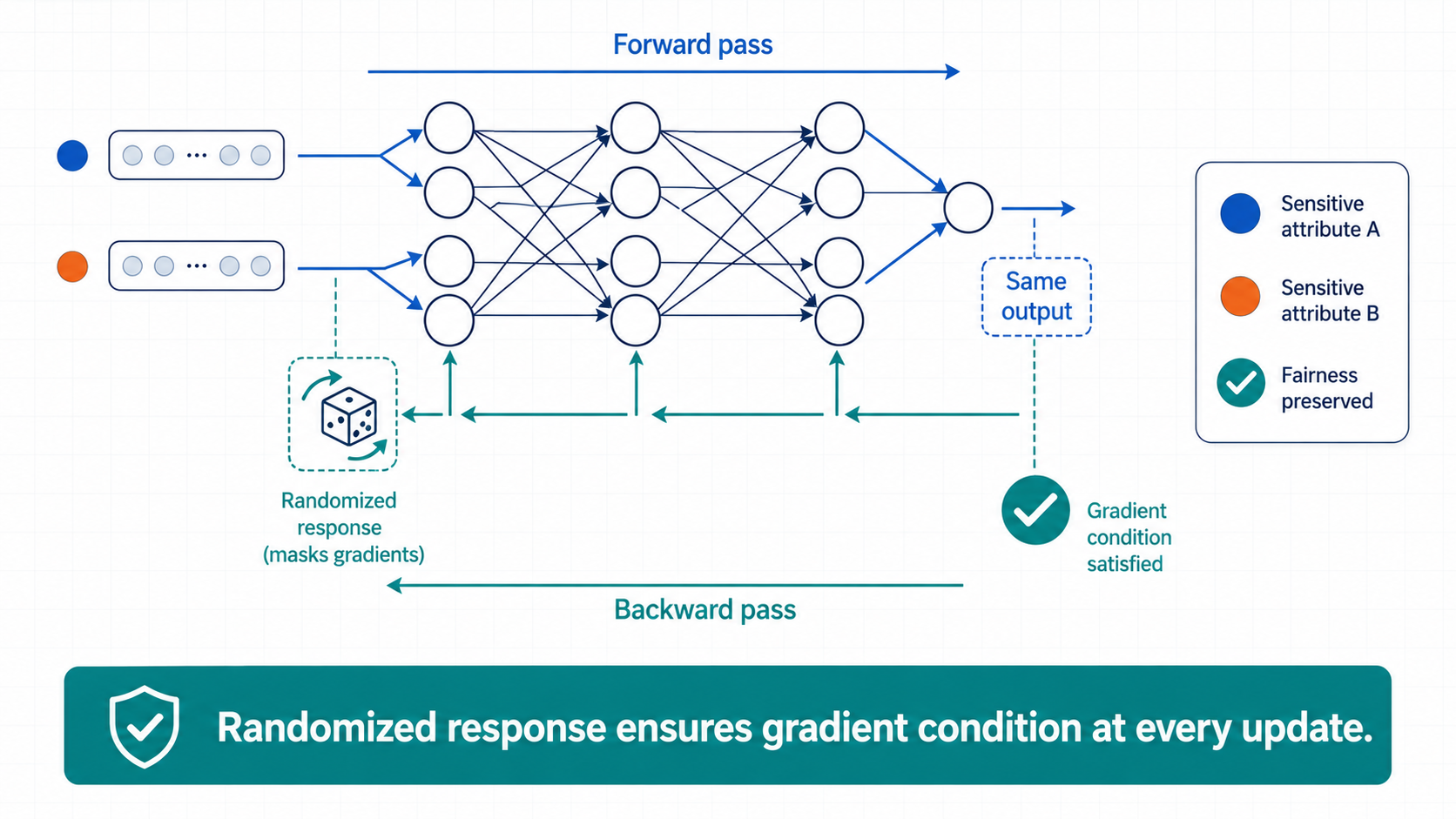
The key technical contribution is a randomized response mechanism applied during training.
When computing gradients, sensitive attribute values are masked using randomized response — a technique from differential privacy. This ensures that the gradient condition in Lemma 3 is satisfied at every update step, without requiring any explicit fairness constraint to be solved during optimization.
The result is a training loop that:
- requires no fairness-specific solver,
- adds minimal computational overhead compared to standard training,
- and produces a model with a certified individual fairness guarantee.
Results
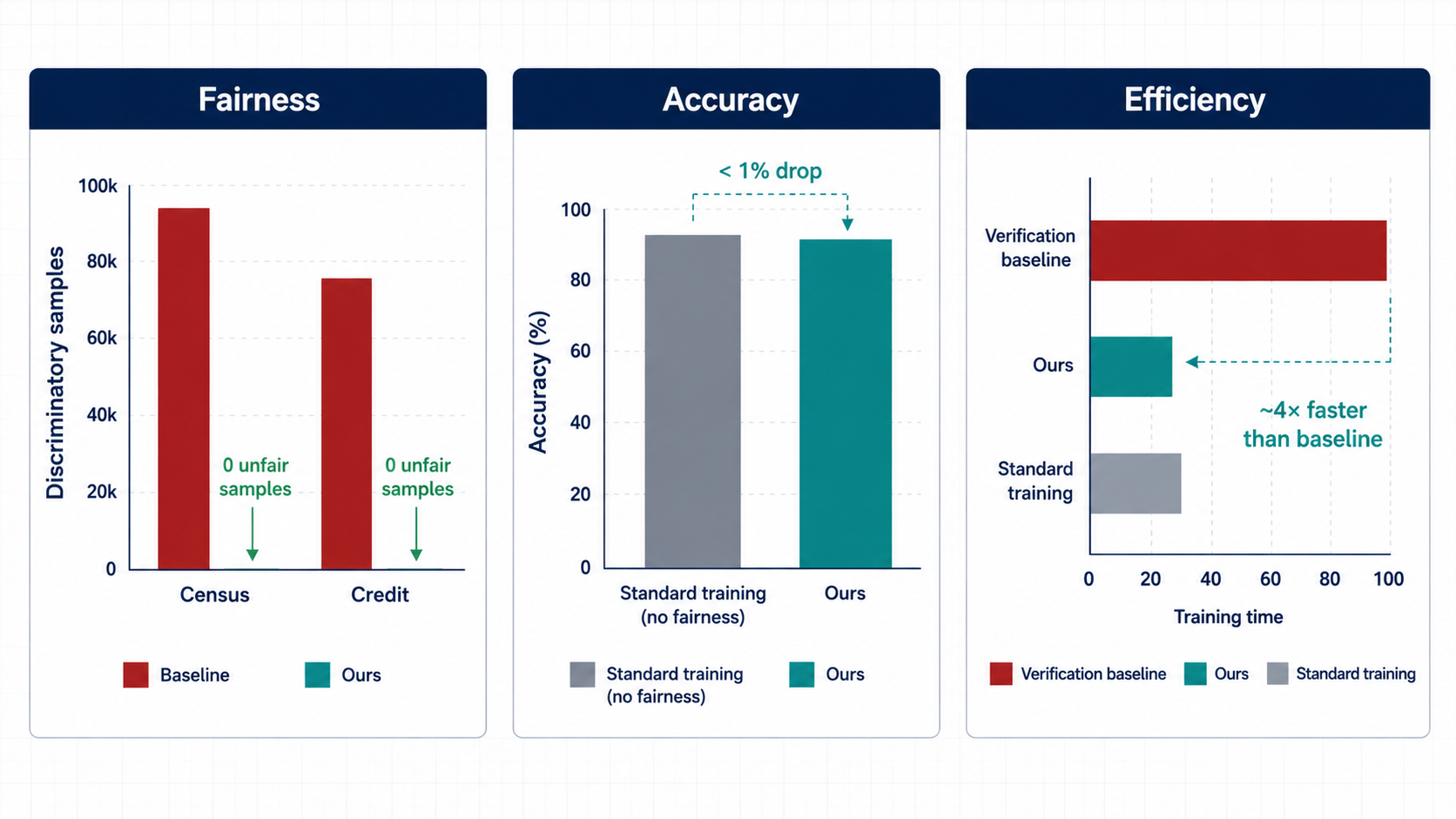
We evaluate our method on standard fairness benchmarks including Census, Credit, and others.
Fairness: Our method achieves perfect individual fairness on all datasets — zero discriminatory samples remain. Baseline methods that combine optimization with post-hoc verification still leave hundreds to thousands of unfair cases.
Accuracy: The accuracy drop is less than one percentage point on average compared to standard training without any fairness constraint. We do not sacrifice utility to obtain fairness.
Efficiency: Training 100 epochs on Census takes comparable time to standard training, and approximately four times faster than the verification-based baseline.
Takeaway
This work shows that individual fairness does not have to be an external constraint imposed on a trained model — it can be a structural property guaranteed by the training process itself.
Takeaway:
Certified individual fairness is achievable through correct-by-construction training, at near-zero overhead and with no post-hoc verification required.
Citation
@article{zhang2025correctbyconstruction,
author = {Zhang, Ruihan and Sun, Jun},
title = {Correct-by-Construction: Certified Individual Fairness through Neural Network Training},
year = {2025},
issue_date = {October 2025},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {9},
number = {OOPSLA2},
url = {https://doi.org/10.1145/3763107},
doi = {10.1145/3763107},
abstract = {Fairness in machine learning is more important than ever as ethical concerns continue to grow. Individual fairness demands that individuals differing only in sensitive attributes receive the same outcomes. However, commonly used machine learning algorithms often fail to achieve such fairness. To improve individual fairness, various training methods have been developed, such as incorporating fairness constraints as optimisation objectives. While these methods have demonstrated empirical effectiveness, they lack formal guarantees of fairness. Existing approaches that aim to provide fairness guarantees primarily rely on verification techniques, which can sometimes fail to produce definitive results. Moreover, verification alone does not actively enhance individual fairness during training. To address this limitation, we propose a novel framework that formally guarantees individual fairness throughout training. Our approach consists of two parts, i.e., (1) provably fair initialisation that ensures the model starts in a fair state, and (2) a fairness-preserving training algorithm that maintains fairness as the model learns. A key element of our method is the use of randomised response mechanisms, which protect sensitive attributes while maintaining fairness guarantees. We formally prove that this mechanism sustains individual fairness throughout the training process. Experimental evaluations confirm that our approach is effective, i.e., producing models that are empirically fair and accurate. Furthermore, our approach is much more efficient than the alternative approach based on certified training (which requires neural network verification during training).},
journal = {Proc. ACM Program. Lang.},
month = oct,
articleno = {329},
numpages = {21},
keywords = {Certified fair training, Individual fairness, Randomised response}
}